

Recent advancements in large language models (LLMs) have brought about significant changes in the field, equipping them with new capabilities like natural conversation, mathematical reasoning, and program synthesis.
However, LLMs still have some inherent limitations. Fixed weights restrict their ability to store information, and their computation capabilities are confined to a static graph and limited context.

Moreover, as the world evolves, LLMs require retraining to update their knowledge and reasoning skills. To overcome these limitations, researchers have started enhancing LLMs with tools. LLMs can utilize search technologies, databases, and computational tools by giving them access to extensive and dynamic knowledge bases and enabling complex computational tasks.
Recently, researchers from UC Berkeley and Microsoft introduced Gorilla, a LLaMA-7B model explicitly designed for API calls. Gorilla relies on self-instruction fine-tuning and retrieval techniques to enable LLMs to accurately select from a large and constantly changing set of tools provided through their APIs and documentation.
The authors create a substantial corpus of APIs, known as APIBench, by gathering machine learning APIs from major model hubs like TorchHub, TensorHub, and HuggingFace. Using self-instruction, they generate pairs of instructions and corresponding APIs.
The fine-tuning process involves converting the data into a user-agent chat-style conversation format and performing standard instruction fine-tuning on the base LLaMA-7B model.

Image description: Gorilla AI showing the correct API
API calls frequently present limitations, which introduce intricacies in the LLM’s understanding and organization of the calls.
For instance, a prompt might demand the LLM to use an image classification model with precise parameter size and accuracy limitations. These difficulties underscore the importance for LLMs to grasp not only the functional explanation of an API call but also to deduce its inherent constraints.
Data Set to look for
The dataset is focused on technology and comprises three domains: Torch Hub, Tensor Hub, and HuggingFace. Each part brings in a wealth of information, showcasing the dataset’s diverse nature.

An additional effort has been made to enhance the dataset’s value and usefulness. Each API in the dataset is accompanied by a carefully crafted set of 10 unique instructions. These instructions are essential guides for both training and evaluation purposes.
This initiative ensures that every API goes beyond simple representation, allowing for more robust usage and analysis.
Retriever-aware training
Gorilla introduces the concept of retriever-aware training, where the instruction-tuned dataset includes an extra field with retrieved API documentation for reference. This approach aims to teach the LLM to understand and answer questions based on the provided documentation.
The authors demonstrate that this technique enables the LLM to adapt to changes in API documentation, leading to improved performance and reduced errors.
During inference, users provide prompts in natural language. Gorilla operates in two modes:
- zero-shot and
- retrieval.
In a zero-shot manner, the prompt is directly given to the Gorilla LLM model, which suggests the appropriate API call to achieve the task or goal. In retrieval mode, the retriever (either BM25 or GPT-Index) retrieves the most up-to-date API documentation from the API Database.
This documentation is combined with the user prompt and a message indicating the reference to the API documentation. The combined input is then fed to Gorilla, which outputs the API to be used. Beyond the concatenation step, no further prompt tuning is performed in this system.
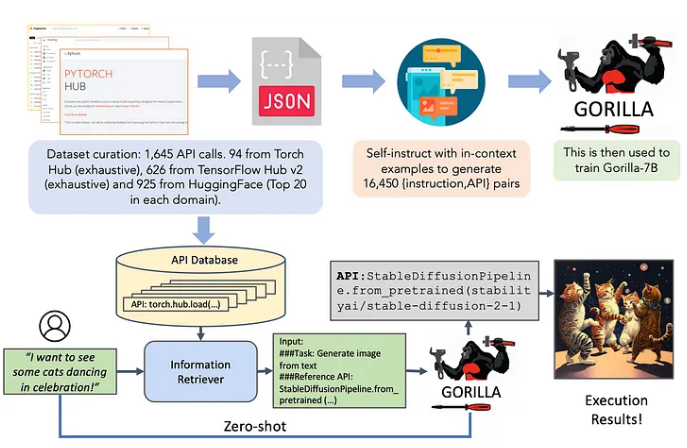
Image description: Gorilla is an LLM that can provide appropriate API calls.
Tree-matching strategy
Inductive program synthesis has succeeded in various domains by creating programs satisfying specific test cases. However, when evaluating API calls, relying solely on test cases falls short because verifying if the code is semantically correct becomes challenging.
To evaluate the model’s performance, a comparison of their functional equivalence is done using the collected dataset. To identify the API called by the LLM in the dataset, an AST (Abstract Syntax Tree) tree-matching strategy is used. By checking if the AST of a candidate API call is a sub-tree of the reference API call, it becomes possible to trace which API is being used.
Defining and identifying hallucinations presents a significant challenge. “The LAST matching process helps identify hallucinations directly. In this context, a hallucination refers to an API call that is not a sub-tree of any API in the database, essentially invoking an entirely imagined tool.”
It’s important to note that this definition of a hallucination differs from invoking an API incorrectly, which is defined as an error.
AST sub-tree matching is crucial in identifying the specific API being called within the dataset. Since API calls can have multiple arguments, each of these arguments needs to be matched. Additionally, considering that Python allows for default arguments, defining which statements to check for each API in the database is essential.
Is AGI on the way?
Gorilla is embarking on limitless workings unlike AI models. Is there a time that AGI is on the verge of a takeover? The questions are many but various answers too. What do you think about it?
Let us know in the comments below.
PureVPN
August 8, 2023
3 years ago







